This is an initiative survey and paper list aiming to employ LLM as the judge for various applications
(Correspondence to: Dawei Li)
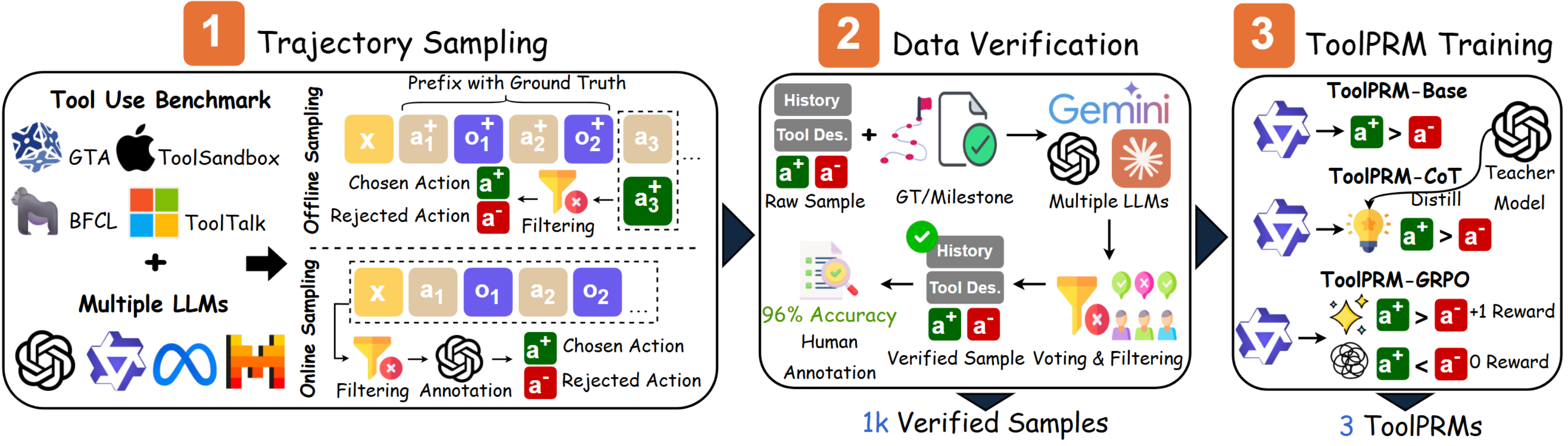
News! We released ToolPRMBench (Accepted by ACL 2026)
- In this work, we introduce ToolPRMBench, a benchmark for evaluating process reward models on tool-use reasoning.
- In this work, we introduce ToolPRMBench, a benchmark for evaluating process reward models on tool-use reasoning.
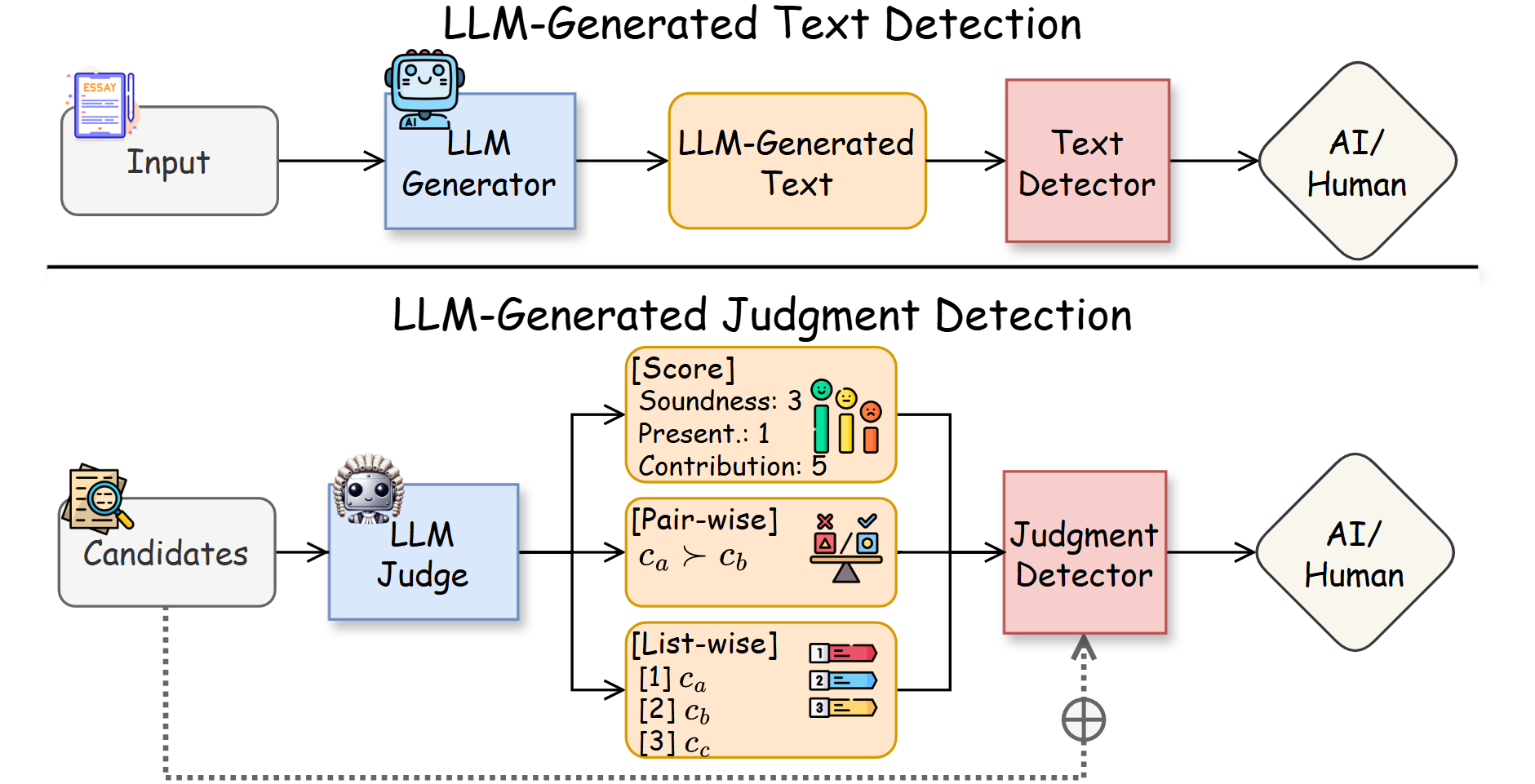
News! We released Who's Your Judge? On the Detectability of LLM-Generated Judgments
- In this work, we propose and formalize the task of judgment detection and systematically investigate the detectability of LLM-generated judgments.
- In this work, we propose and formalize the task of judgment detection and systematically investigate the detectability of LLM-generated judgments.
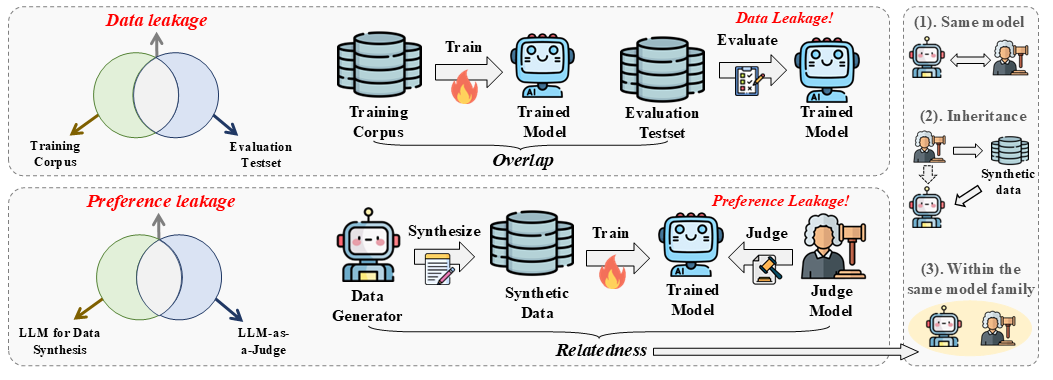
News! We released Preference Leakage: A Contamination Problem in LLM-as-a-judge (Accepted by ICLR 2026)
- In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness of data generator and evaluator LLMs.
(Arixiv Version) From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge (Accepted by EMNLP 2025)
- In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness of data generator and evaluator LLMs.
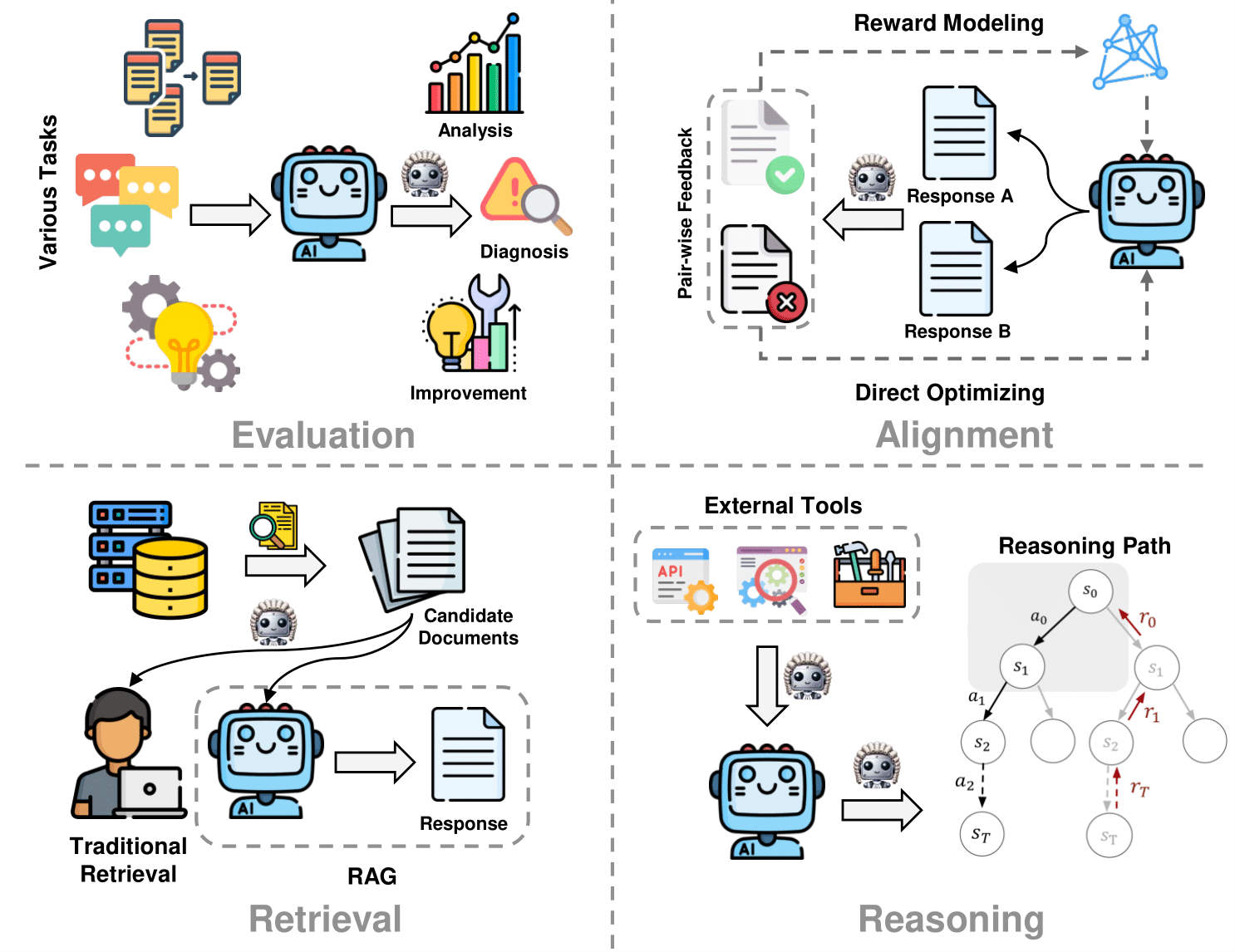
- A survey of the opportunities (What, How and Where to judge) and challenges (limitations and bias of judge LLMs) of LLM-as-a-judge.
- In this survey, we delve into the details of LLM-as-a-judge, aiming to provide a comprehensive overview of LLM-based judgment, including judgment attributes, methodologies, applications and benchmarks.